ML PHISH DETECTOR
"Securing the Web, One URL at a Time"
Developed as an AI/ML Showcase Project
MOHAMMAD AFROZ ALI
Data Science | Machine Learning Enthusiast
Table of Contents
About Me
MOHAMMAD AFROZ ALI
Aspiring SDE, AIML Intern
🎓 Education
Final Semester – B.Tech (Information Technology) - 8.0/10 CGPA
Muffakham Jah College of Engineering & Technology
Focused on:
AI/ML • Software Engineering • Cloud Technologies
💡 Interests
Keen on Artificial Intelligence & Machine Learning
Focus on building end-to-end solutions that combine ML with software engineering best practices
Technical Proficiency
Introduction
Phishing attacks represent a significant cybersecurity threat, targeting users through deceptive websites that mimic legitimate services to steal sensitive information. This project delivers an end-to-end machine learning solution to accurately identify phishing URLs using their structural and behavioral characteristics.
Project Motivation
With the increasing sophistication of phishing attacks, traditional rule-based detection methods often fall short. Machine learning approaches can adapt to evolving threats by identifying subtle patterns in URL characteristics, enabling more robust protection for users navigating the web.
Dataset Information
The project utilizes a comprehensive dataset containing 30 features extracted from URLs, all designed to capture different aspects of potential phishing indicators. These features include:
The target variable Result identifies URLs as either legitimate (0) or phishing (1).
Project Overview
Key Features of the Project
Modular Pipeline Architecture
Each component (ingestion, validation, transformation, training, prediction) is implemented as a separate module with clear interfaces, enabling maintainability and extensibility.
Automated Workflow
Complete automation from data ingestion to model deployment, with robust logging and exception handling at each stage to ensure reliability.
Experiment Tracking
Integration with MLflow for tracking experiments, storing metrics, and managing model artifacts with version control.
Cloud-Native Design
Seamless deployment to AWS infrastructure with storage in S3, containerization via Docker, and CI/CD through GitHub Actions.
Schema Validation
Strict schema enforcement using YAML configuration to ensure data quality and consistency across the pipeline.
Version Control Integration
DAGsHub integration for model versioning and experiment tracking with Git-like capabilities for ML artifacts.
Project Flow Overview
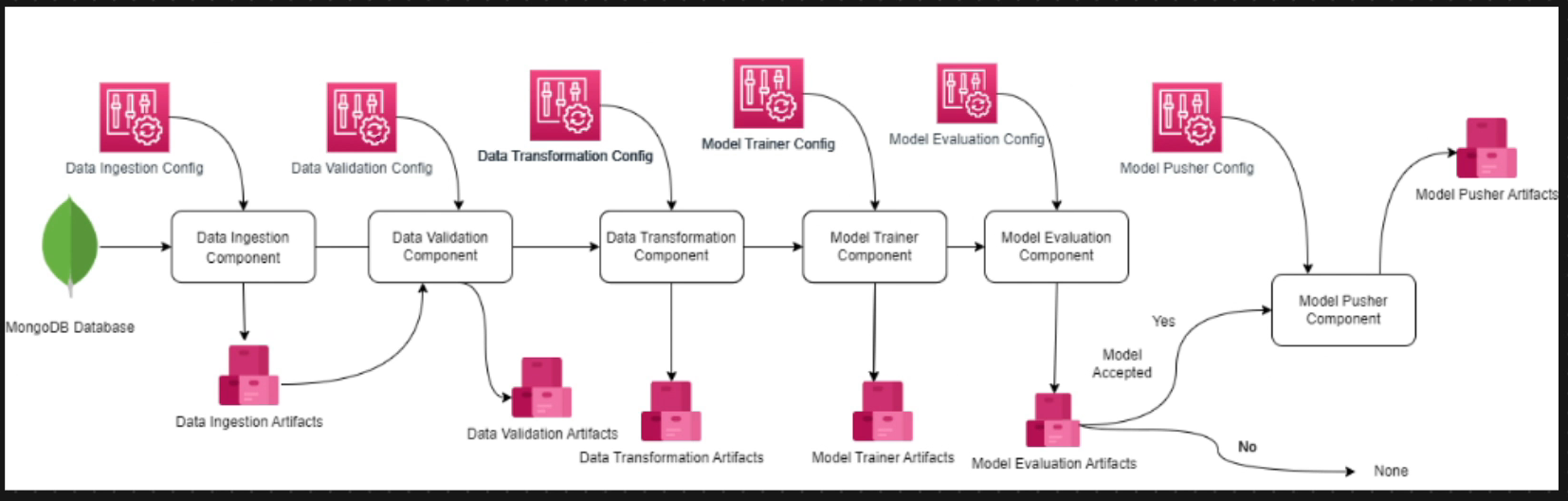
- Data Ingestion: Extract data from MongoDB, validate schema, and split into train/test sets
- Data Validation: Verify dataset schema, check for drift between train/test datasets
- Data Transformation: Handle missing values with KNN imputation, prepare features for training
- Model Training: Benchmark multiple classifiers with hyperparameter tuning
- Model Evaluation: Assess performance using classification metrics (F1, precision, recall)
- Experiment Tracking: Log metrics, parameters, and artifacts to MLflow
- Model Serialization: Save preprocessor and best model for deployment
- Containerization: Package application with Docker for consistent deployment
- CI/CD Pipeline: Automate testing, building, and deployment with GitHub Actions
- Cloud Deployment: Deploy to AWS (EC2/ECR) with appropriate IAM roles
Data Ingestion
Data Sources and Integration
The data ingestion pipeline extracts phishing URL data from a MongoDB database, which serves as the primary data source. The implementation leverages PyMongo to connect to the database and retrieve the dataset using the configured database and collection names.
# MongoDB Connection and Data Export
def export_collection_as_dataframe(self):
database_name = self.data_ingestion_config.database_name
collection_name = self.data_ingestion_config.collection_name
self.mongo_client = pymongo.MongoClient(MONGO_DB_URL)
collection = self.mongo_client[database_name][collection_name]
df = pd.DataFrame(list(collection.find()))
if "_id" in df.columns.to_list():
df = df.drop(columns=["_id"], axis=1)
df.replace({"na": np.nan}, inplace=True)
return df
Train-Test Split
After extraction, the data is split into training and test sets using scikit-learn's train_test_split function with a configurable split ratio. This ensures that model evaluation is performed on unseen data.
Feature Store Integration
The raw dataset is persisted to a feature store file path for future reference and to maintain a historical record of the data used in each training run. This supports reproducibility and model versioning.
Data Validation
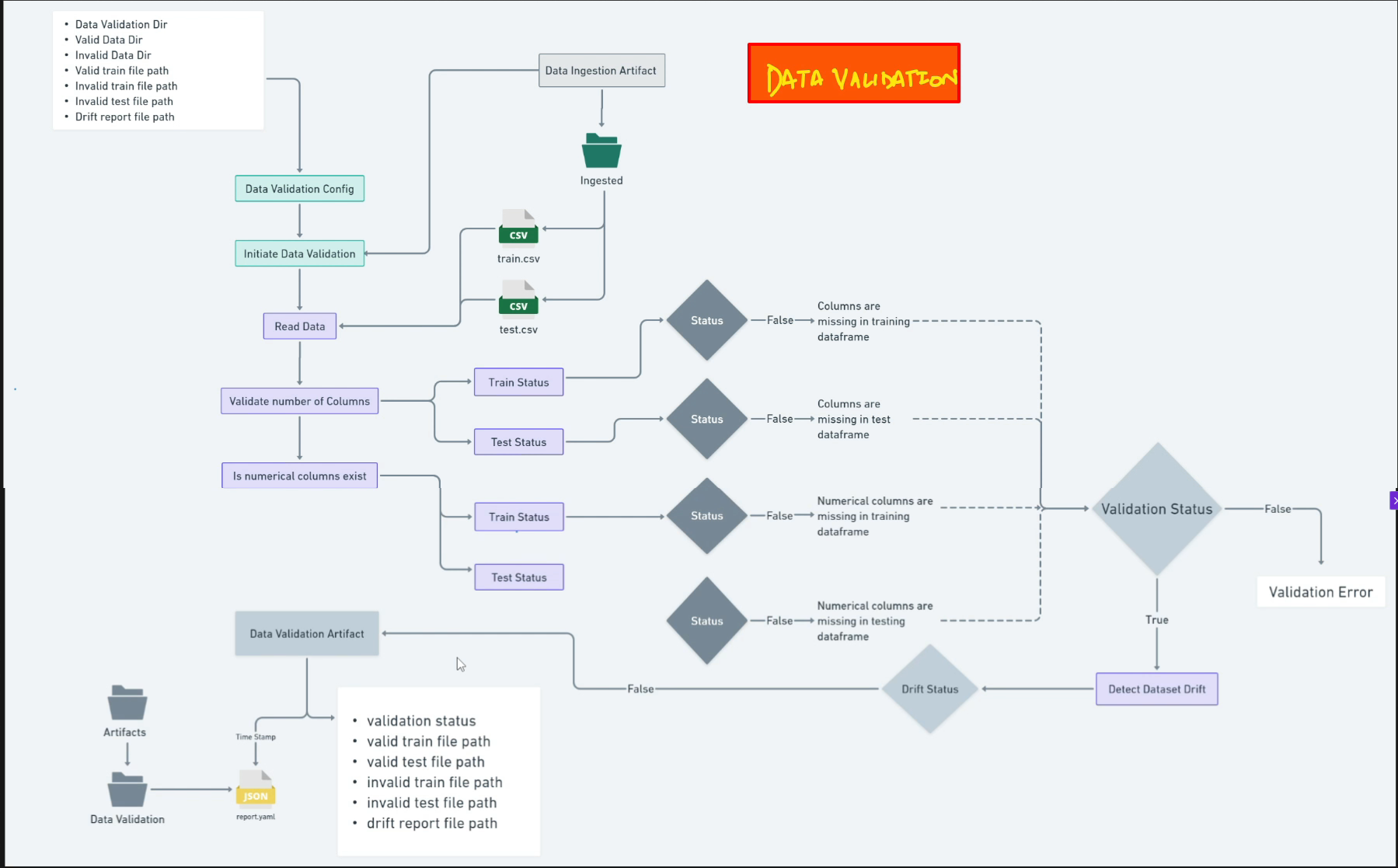
Schema-Based Validation
Data validation is a critical step to ensure the quality and integrity of the input data. The process involves validating the dataset against a predefined schema (schema.yaml) that specifies the expected column names and data types.
# Column Validation Function
def validate_number_of_columns(self, dataframe: pd.DataFrame) -> bool:
try:
number_of_columns = len(self._schema_config)
logging.info(f"Required number of columns: {number_of_columns}")
logging.info(f"Data frame has columns: {len(dataframe.columns)}")
if len(dataframe.columns) == number_of_columns:
return True
return False
except Exception as e:
raise NetworkSecurityException(e, sys)
Drift Detection
The validation process also includes checking for data drift between the training and test datasets using the Kolmogorov-Smirnov statistical test. This helps identify shifts in data distribution that could impact model performance.
For each feature, the p-value from the KS test is compared against a predefined threshold (0.05). Values below this threshold indicate significant drift that may require attention.
Validation Artifacts
- Validated train and test datasets
- Drift detection report (YAML format)
- Validation status indicator
Data Transformation
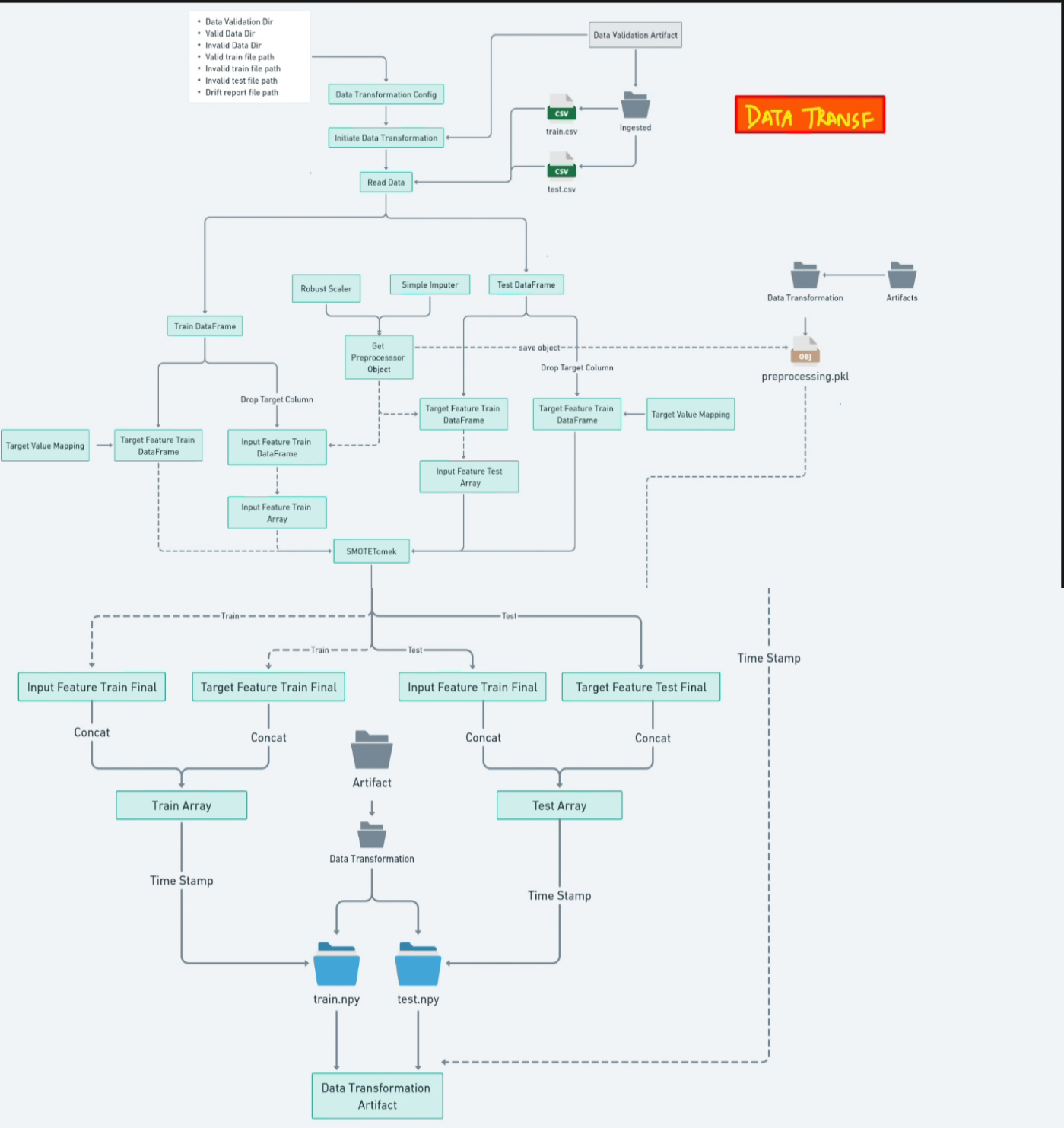
Feature Processing Pipeline
Data transformation is a crucial step that prepares the raw input features for model training. The process focuses on handling missing values and ensuring consistent feature representation across training and inference.
KNN Imputation for Missing Values
The transformation pipeline uses scikit-learn's KNNImputer to handle missing values in the dataset. This approach replaces missing values with the values from the K nearest neighbors in the feature space, which preserves the relationships between features better than simpler methods like mean or median imputation.
# KNN Imputer Configuration
DATA_TRANSFORMATION_IMPUTER_PARAMS: dict = {
"missing_values": np.nan,
"n_neighbors": 3,
"weights": "uniform",
}
The imputer is configured with n_neighbors=3 and uniform weights, meaning it uses the 3 closest neighbors with equal weighting to determine the replacement value for each missing data point.
Transformation Process
The transformation process follows these steps:
- Load validated training and testing datasets
- Separate features (X) from target variable (y)
- Handle negative target values (converting -1 to 0 for binary compatibility)
- Create and fit the KNN preprocessing pipeline on training features
- Transform both training and testing feature sets
- Combine transformed features with target variables
- Save the transformed datasets as NumPy arrays (.npy files)
- Serialize the preprocessor object for future use during inference
Transformation Artifacts
- transformed_train.npy: Processed training dataset
- transformed_test.npy: Processed test dataset
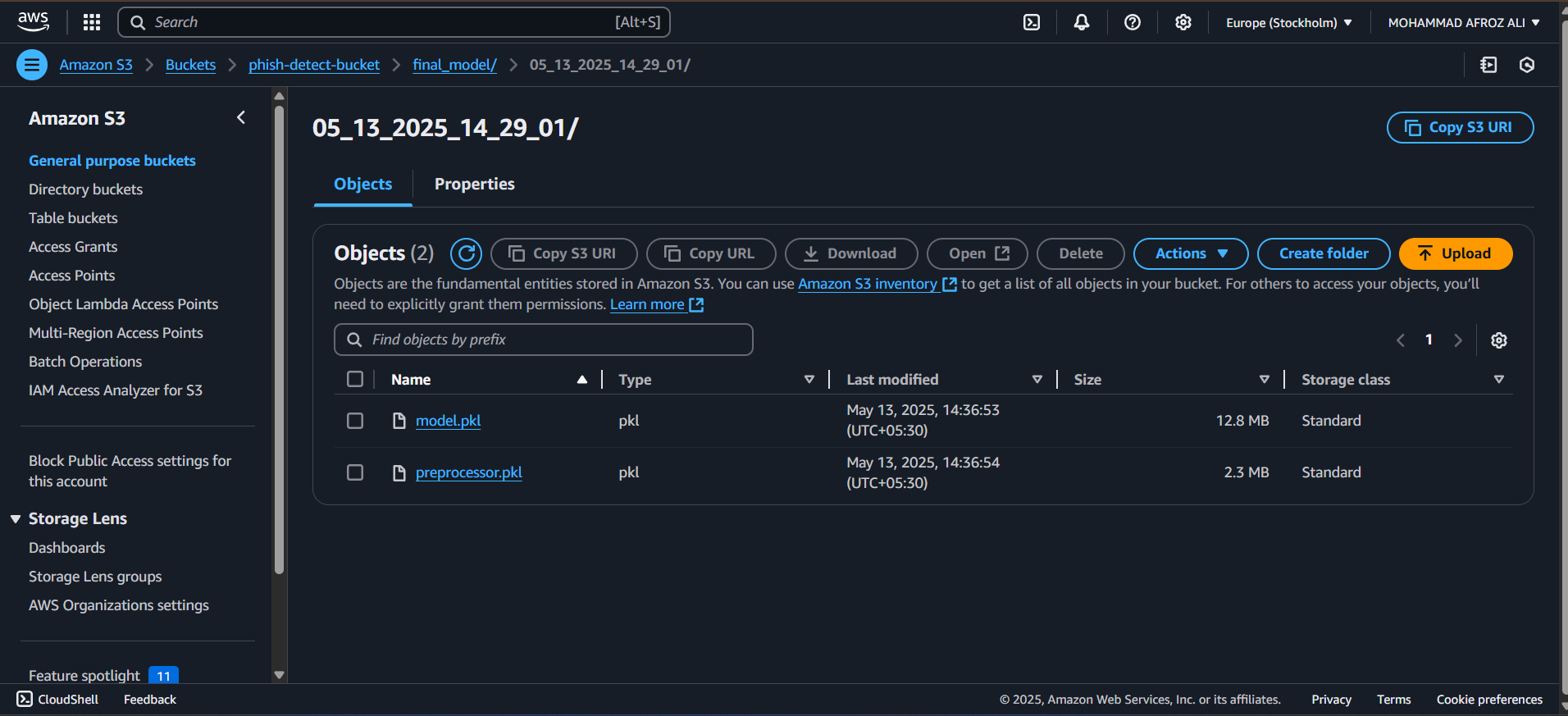
- preprocessor.pkl: Serialized preprocessing pipeline for consistent transformation during inference
Feature Importance for Phishing Detection
The 30 features in the dataset capture various URL and webpage characteristics that are indicative of phishing attempts. These include structural elements (presence of IP addresses, URL length), security indicators (SSL certificates, domain registration details), and behavioral aspects (redirect patterns, form submission targets).
By maintaining these features' integrity through proper transformation, the model can effectively learn the patterns that distinguish legitimate websites from phishing attempts.
Model Training & Hyperparameter Tuning
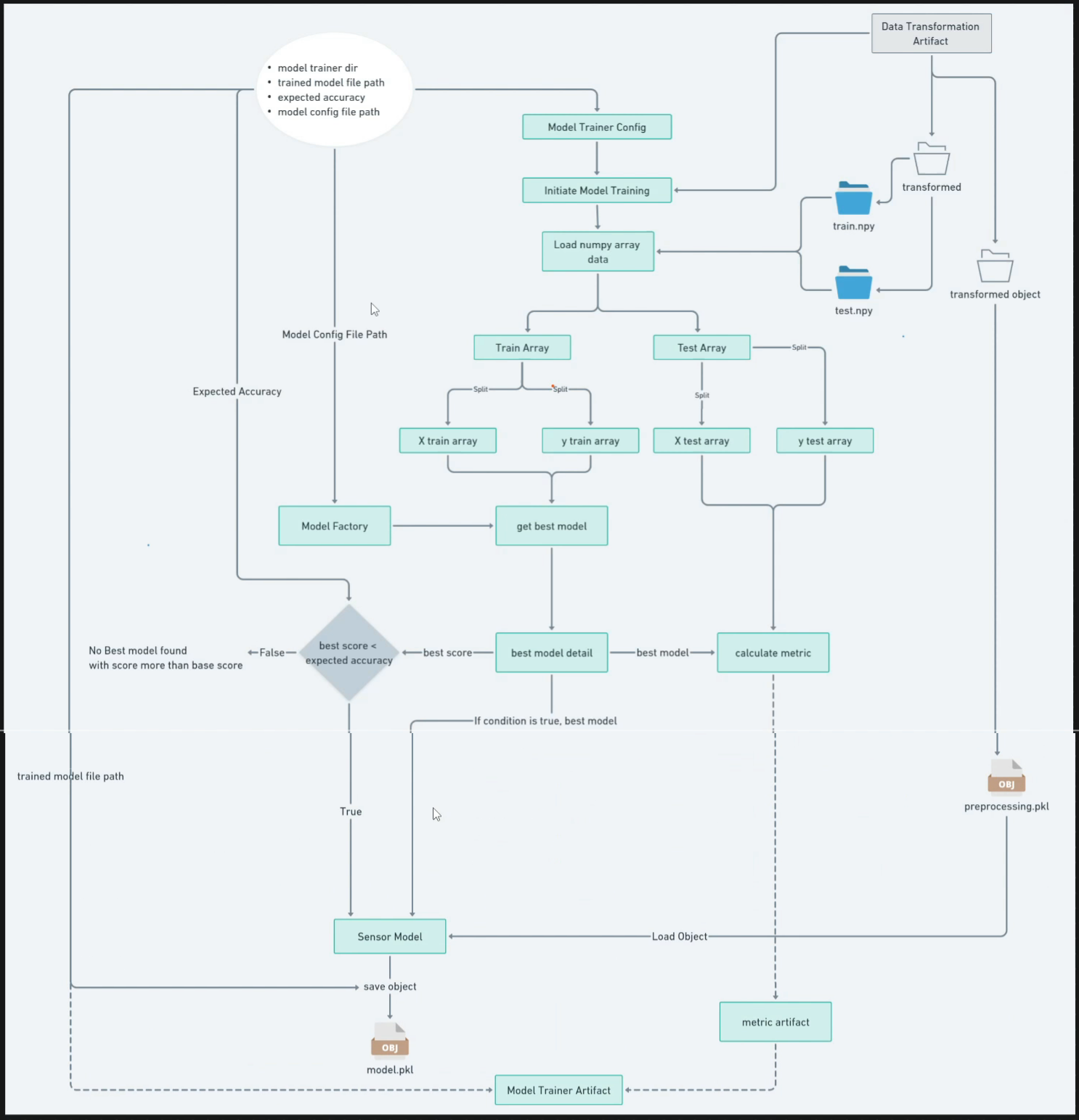
Model Selection Strategy
The training pipeline evaluates multiple classification algorithms to identify the most effective approach for phishing detection. Each algorithm is rigorously tested with various hyperparameter configurations through GridSearchCV to determine the optimal settings.
Candidate Models
Random Forest
Ensemble of decision trees that performs well on structured data with mixed feature types and importance.
Tuned parameters: n_estimators
Decision Tree
Single decision tree offering good interpretability and feature importance rankings.
Tuned parameters: criterion
Gradient Boosting
Sequential ensemble method that builds trees to correct errors of previous trees.
Tuned parameters: learning_rate, subsample, n_estimators
Logistic Regression
Linear model for binary classification that provides probability estimates.
Default parameters
AdaBoost
Boosting algorithm that weights misclassified samples higher in subsequent iterations.
Tuned parameters: learning_rate, n_estimators
Hyperparameter Tuning
Each model undergoes extensive hyperparameter tuning to optimize performance. The implementation uses scikit-learn's GridSearchCV to perform exhaustive search over specified parameter values for each classifier.
# Parameter Grid Example
params = {
"Random Forest": {
'n_estimators': [8, 16, 32, 128, 256]
},
"Gradient Boosting": {
'learning_rate': [.1, .01, .05, .001],
'subsample': [0.6, 0.7, 0.75, 0.85, 0.9],
'n_estimators': [8, 16, 32, 64, 128, 256]
},
"AdaBoost": {
'learning_rate': [.1, .01, .001],
'n_estimators': [8, 16, 32, 64, 128, 256]
}
}
Best Model Selection
After evaluating all models with their optimal hyperparameters, the best performing model is selected based on test set performance. This model is then wrapped with the preprocessor to create a unified prediction pipeline that handles both preprocessing and inference.
Network Model Wrapper Class
A custom NetworkModel class encapsulates both the preprocessor and the trained model to ensure consistent feature transformation during inference:
class NetworkModel:
def __init__(self, preprocessor, model):
self.preprocessor = preprocessor
self.model = model
def predict(self, x):
x_transform = self.preprocessor.transform(x)
return self.model.predict(x_transform)
Model Evaluation
Performance Metrics
The project uses comprehensive classification metrics to evaluate model performance, with a focus on balanced assessment that considers both false positives and false negatives:
F1 Score
Harmonic mean of precision and recall, providing a balanced measure for classification performance.
Precision
Ratio of correctly predicted positive observations to total predicted positives, measuring false positive rate.
Recall
Ratio of correctly predicted positive observations to all actual positives, measuring false negative rate.
Evaluation Process
The evaluation framework assesses each model on both training and test datasets to monitor for overfitting and ensure generalization capability. The metrics are logged in MLflow for experiment tracking and comparison.
# Classification Metric Function
def get_classification_score(y_true, y_pred):
f1 = f1_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
return ClassificationMetricArtifact(
f1_score=f1,
precision_score=precision,
recall_score=recall
)
Drift Analysis
Beyond typical model evaluation, the pipeline also analyzes data drift between training and testing datasets. This helps identify potential distribution shifts that could impact model performance in production.
The Kolmogorov-Smirnov test is used to compare feature distributions, with a threshold of 0.05 for the p-value to flag significant drift.
Experiment Tracking with MLflow
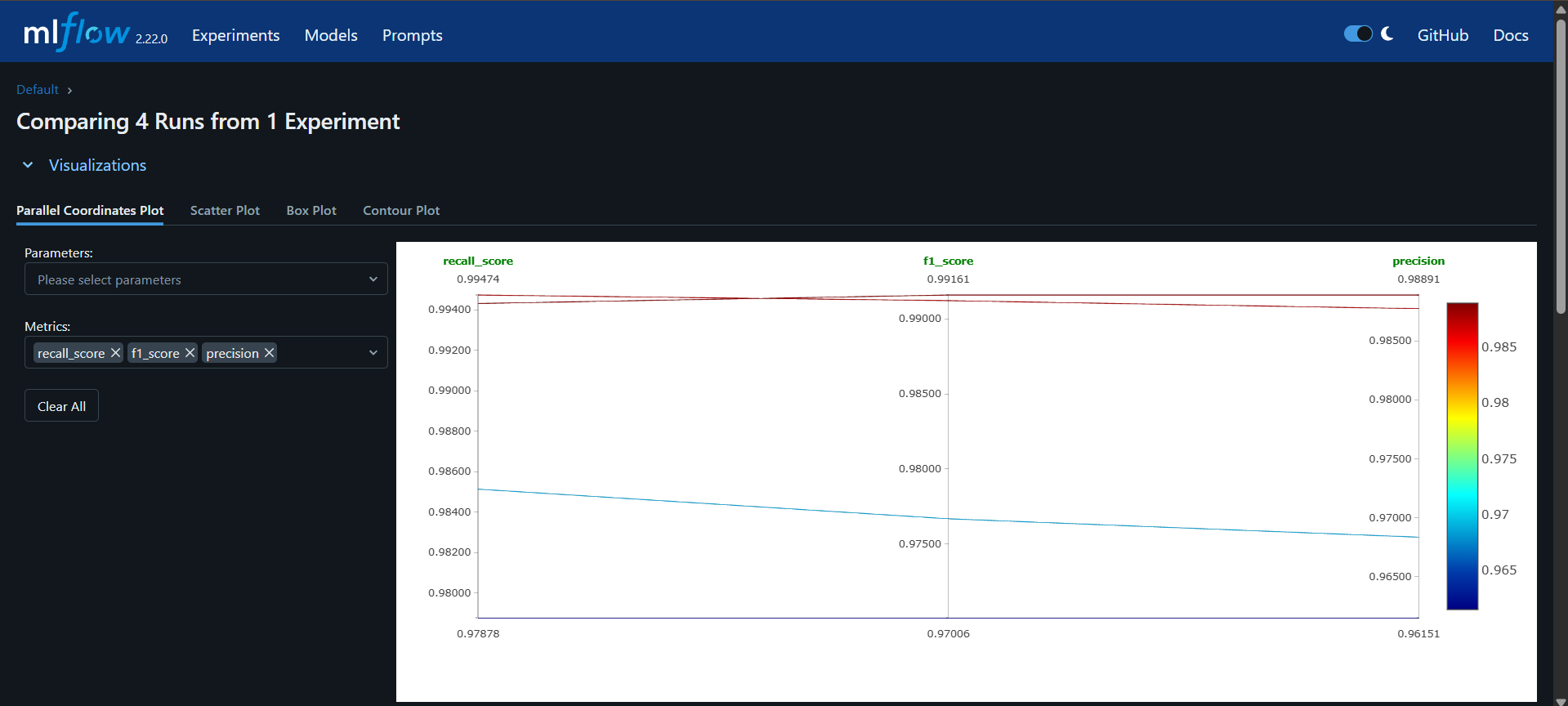
MLflow Integration
MLflow is integrated into the training pipeline to track experiments, metrics, parameters, and model artifacts. This provides versioning capabilities and reproducibility for the machine learning workflow.
# MLflow Tracking with DAGsHub Integration
import mlflow
import dagshub
dagshub.init(repo_owner='MOHD-AFROZ-ALI', repo_name='ml-phish-detector', mlflow=True)
def track_mlflow(self, best_model, classificationmetric):
with mlflow.start_run():
f1_score = classificationmetric.f1_score
precision_score = classificationmetric.precision_score
recall_score = classificationmetric.recall_score
mlflow.log_metric("f1_score", f1_score)
mlflow.log_metric("precision", precision_score)
mlflow.log_metric("recall_score", recall_score)
mlflow.sklearn.log_model(best_model, "model")
Experiment Management
Each training run is tracked as a separate experiment in MLflow, capturing:
Tracked Parameters
- Model hyperparameters
- Training parameters (train-test split ratio, etc.)
- Preprocessing configuration
Tracked Metrics
- F1 score (train and test)
- Precision score (train and test)
- Recall score (train and test)
DAGsHub Integration
The project leverages DAGsHub for remote storage of ML experiments, providing a GitHub-like interface for ML artifacts. This enables team collaboration and experiment comparison in a centralized repository.
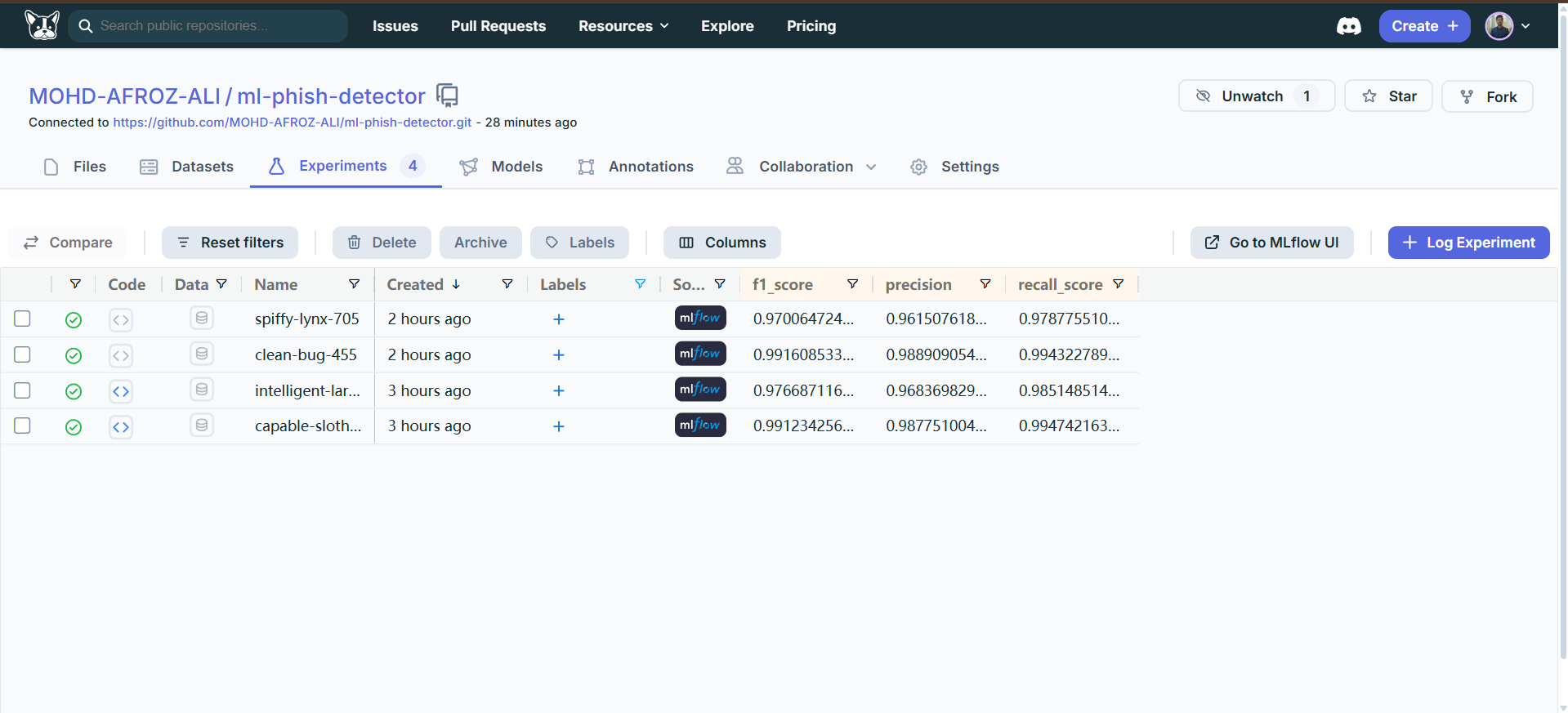
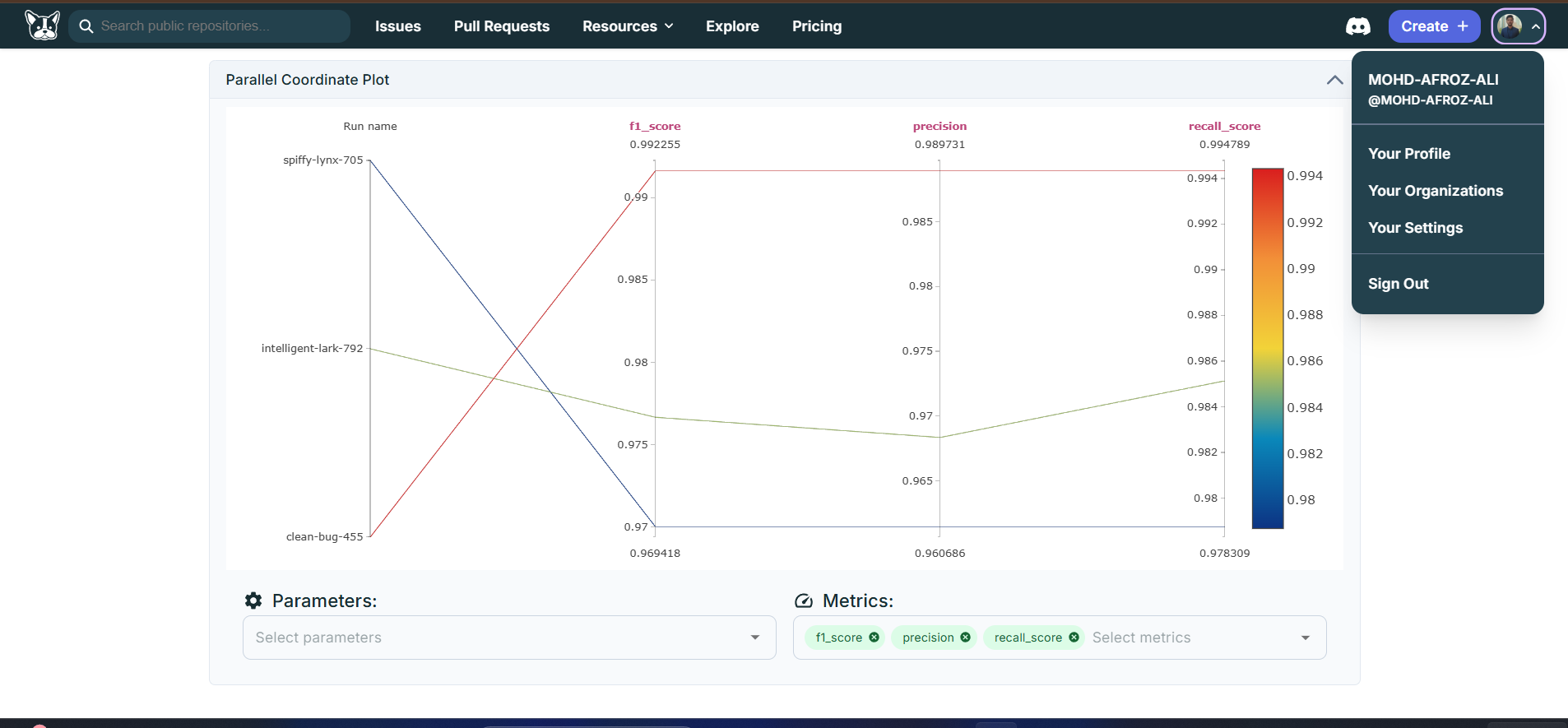
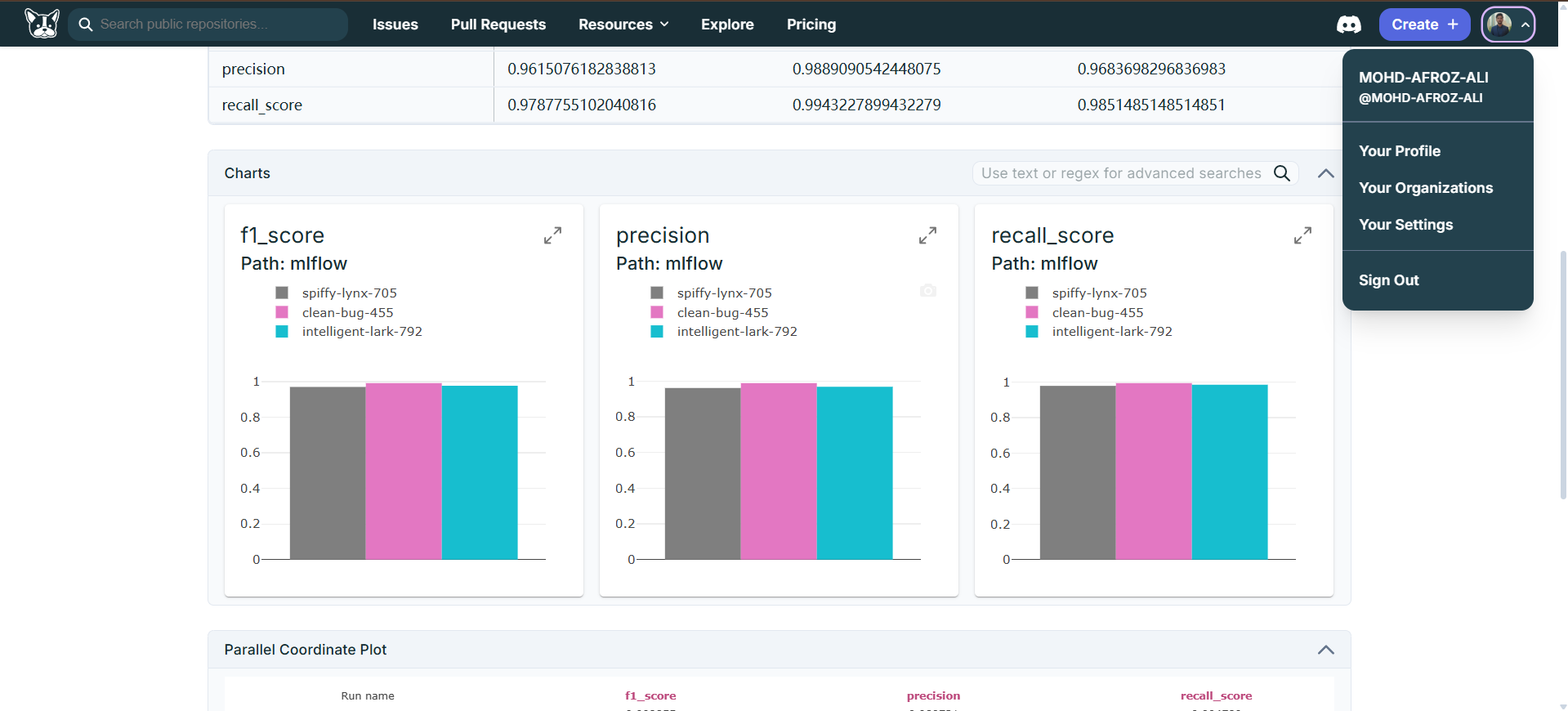
Deployment
Docker Containerization
The application is containerized using Docker to ensure consistent deployment across environments. The Dockerfile packages the entire application, including dependencies and trained models.
FROM python:3.10-slim-buster WORKDIR /app COPY . /app RUN apt update -y && apt install awscli -y RUN apt-get update && pip install -r requirements.txt CMD ["python3", "app.py"]
The containerized application can be deployed to any environment that supports Docker, ensuring consistency between development, testing, and production environments.
CI/CD Pipeline
A CI/CD pipeline is implemented using GitHub Actions to automate the testing, building, and deployment process. The workflow is triggered on each push to the main branch and performs the following tasks:
- Code linting and formatting checks
- Unit test execution
- Docker image building
- Publishing to AWS ECR (Elastic Container Registry)
- Deployment to AWS ECS (Elastic Container Service) or EC2
Cloud Deployment (AWS)
The project utilizes AWS services for cloud deployment, with the following components:
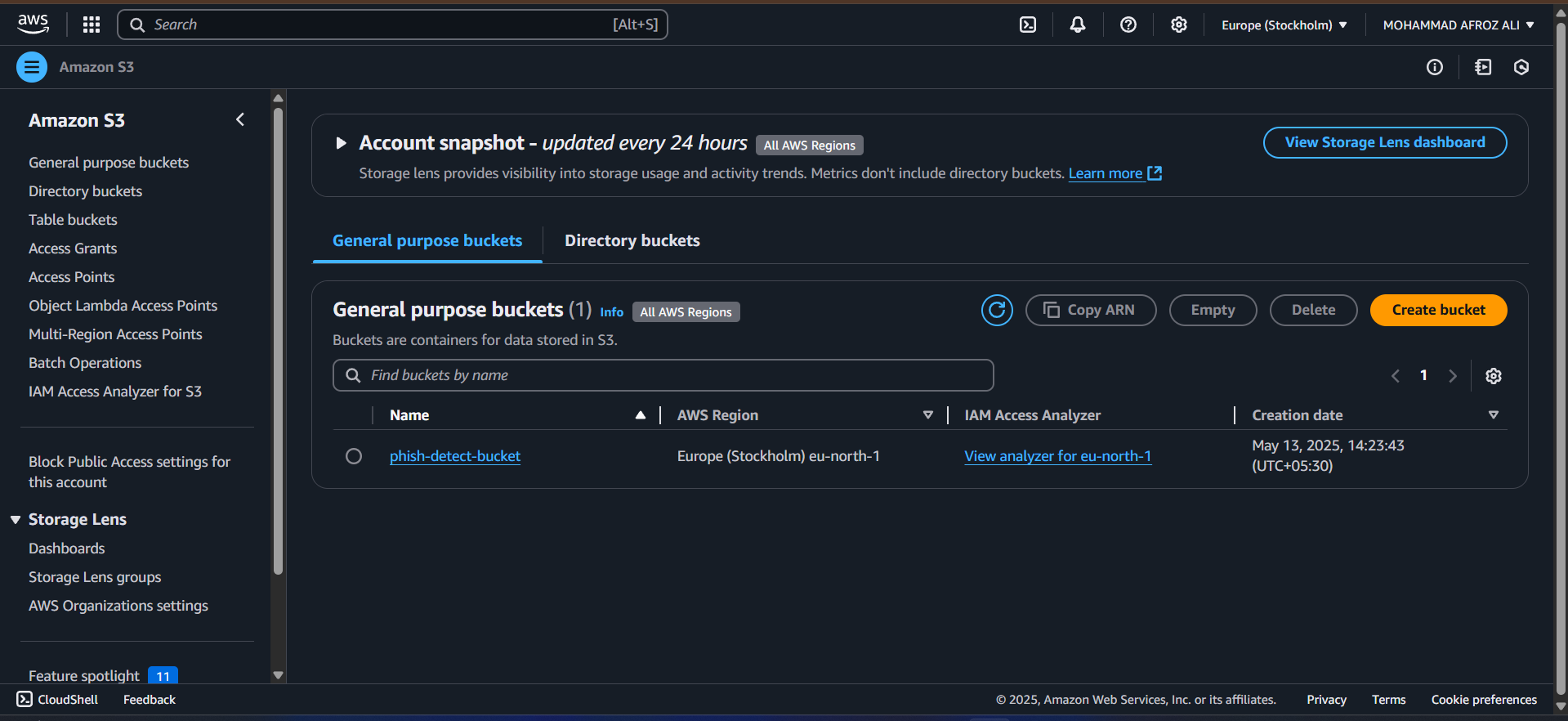
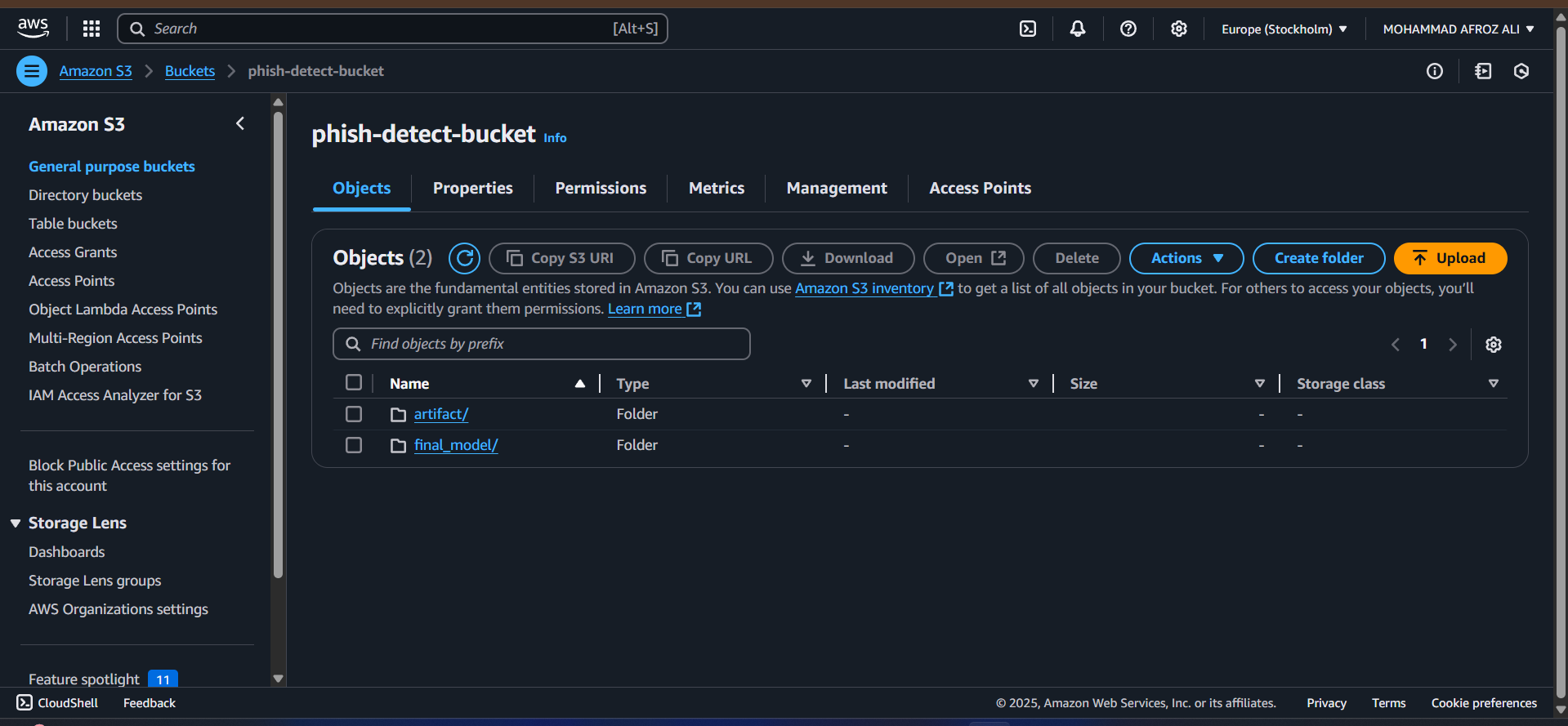
S3 (Simple Storage Service)
Used for storing data artifacts, model versioning, and dataset backups. The S3 syncer module facilitates seamless file transfer between local and cloud storage.
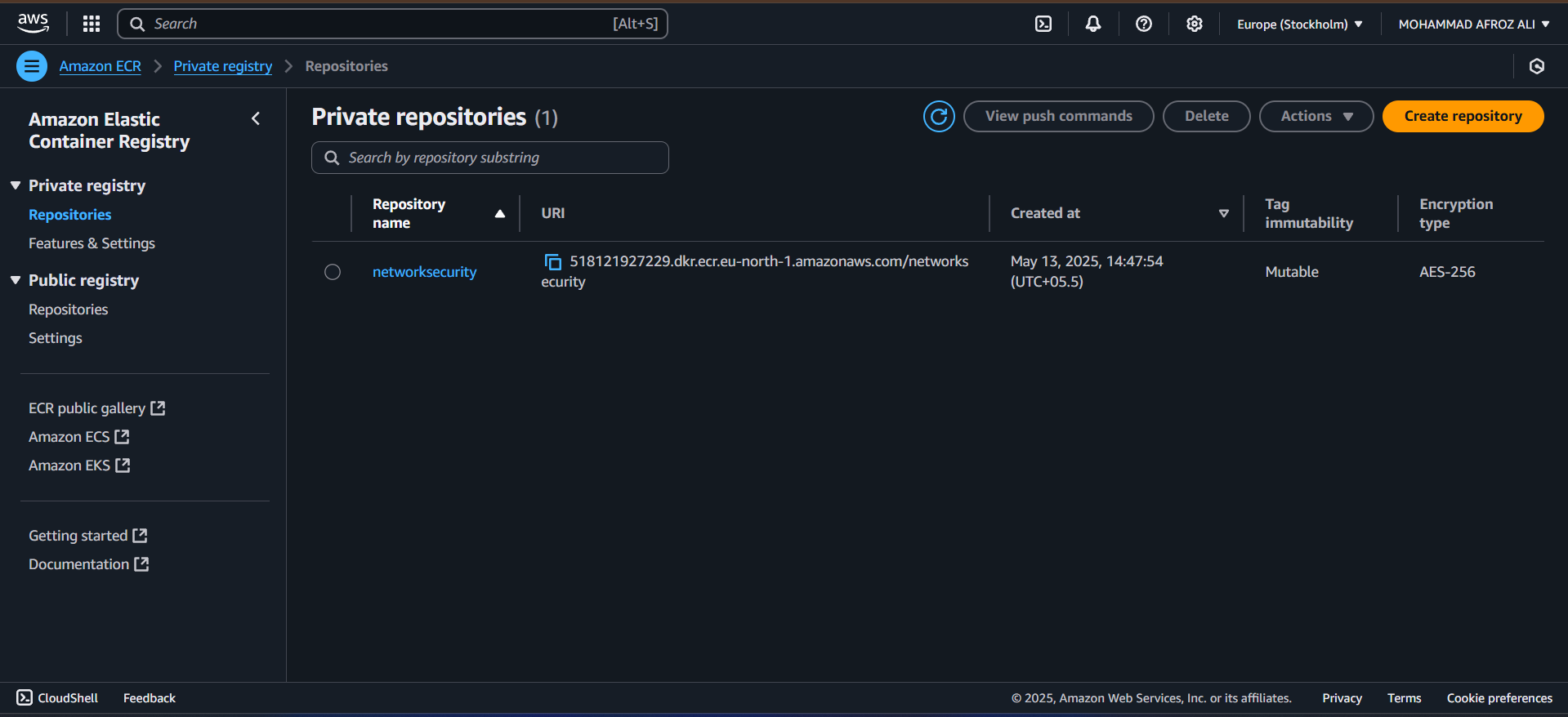
ECR (Elastic Container Registry)
Hosts Docker images built by the CI/CD pipeline, providing version control and secure storage for container images.
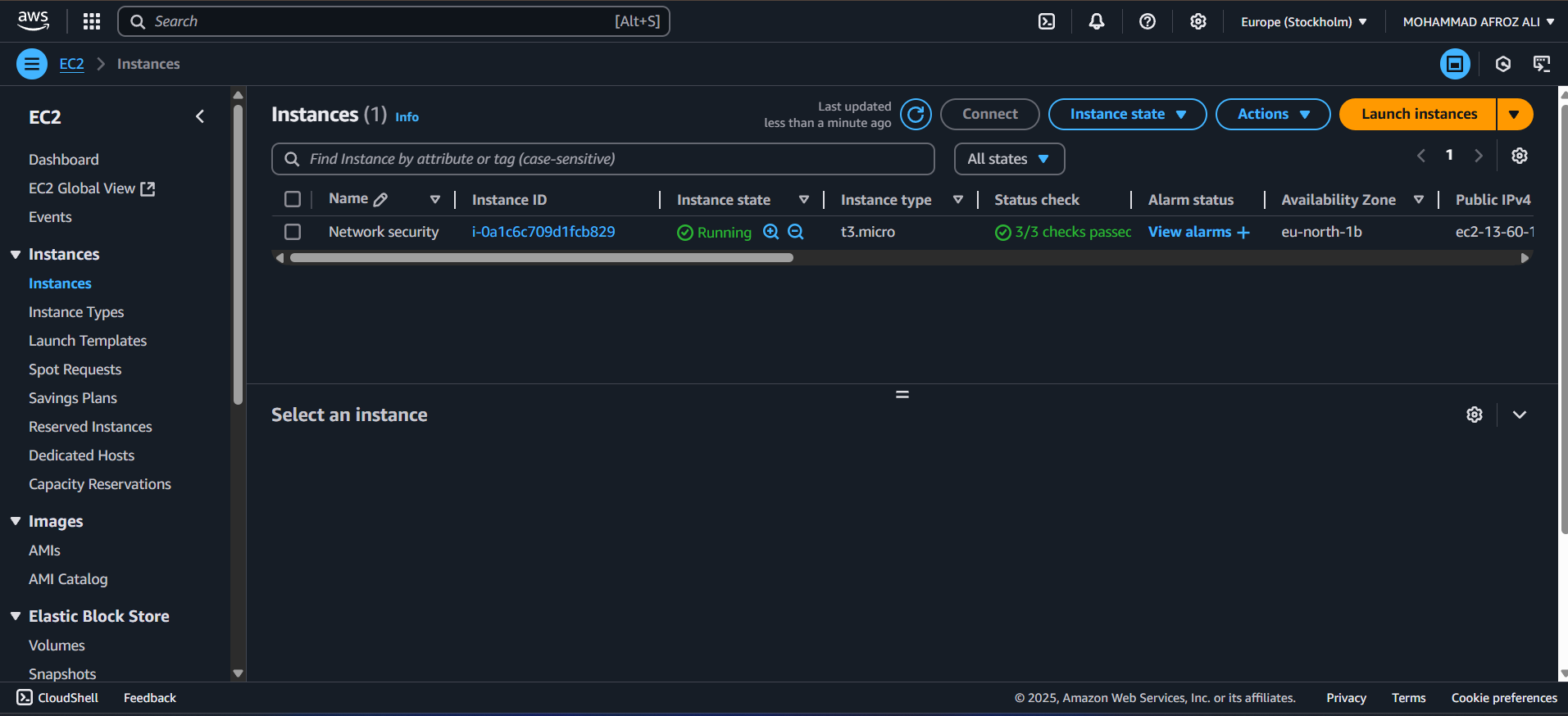
EC2 (Elastic Compute Cloud)
Hosts the deployed application, providing scalable compute resources for the phishing detection service.
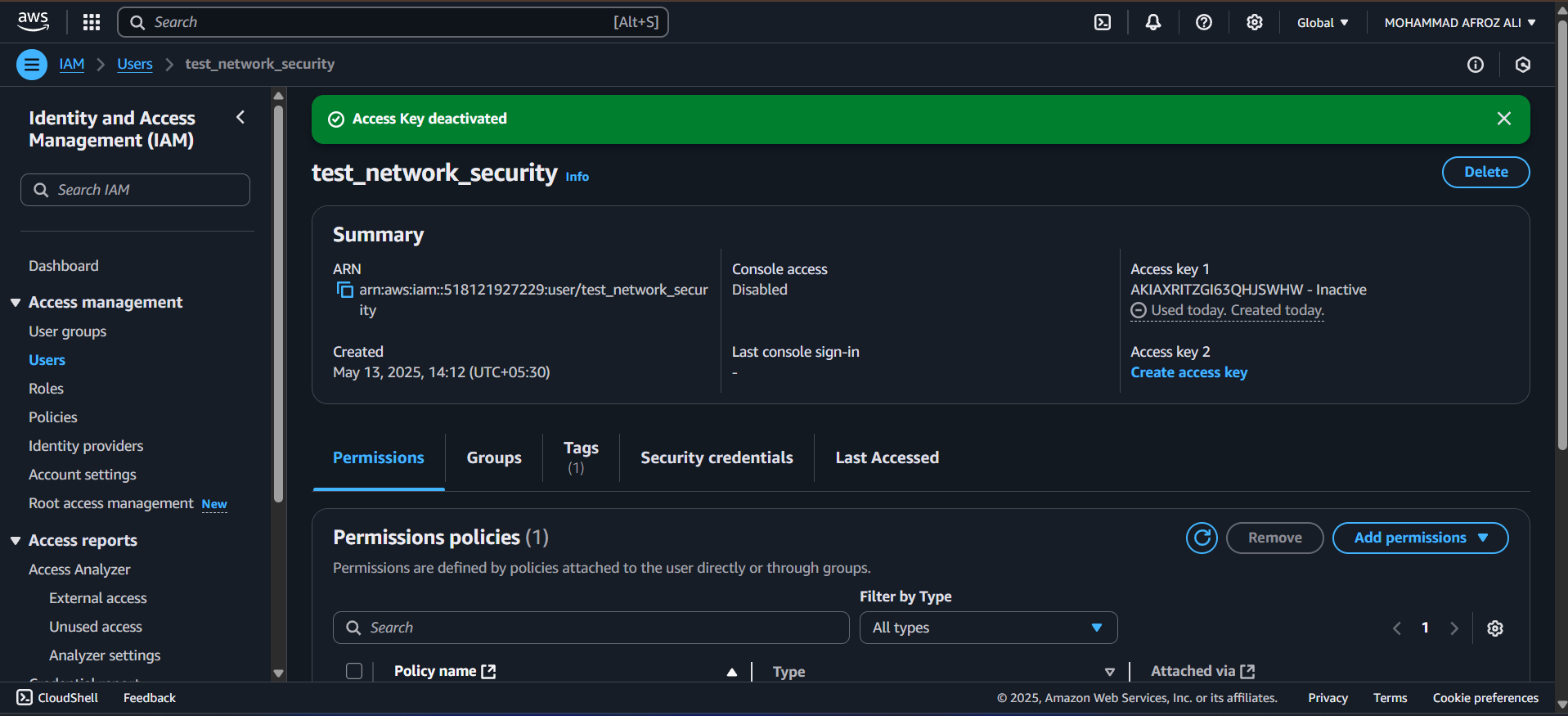
IAM (Identity and Access Management)
Manages access permissions for different AWS services, ensuring secure operation with least privilege principles.
Web Service API
The deployed application exposes a FastAPI endpoint that accepts URL features for analysis and returns phishing probability. This RESTful API allows integration with other systems and services.
@app.post("/predict")
async def predict_route(request: Request, file: UploadFile = File(...)):
try:
df = pd.read_csv(file.file)
preprocesor = load_object("final_model/preprocessor.pkl")
final_model = load_object("final_model/model.pkl")
network_model = NetworkModel(preprocessor=preprocesor, model=final_model)
y_pred = network_model.predict(df)
df['predicted_column'] = y_pred
df.to_csv('prediction_output/output.csv')
table_html = df.to_html(classes='table table-striped')
return templates.TemplateResponse("table.html", {"request": request, "table": table_html})
except Exception as e:
raise NetworkSecurityException(e, sys)
Conclusion
The ML Phish Detector project demonstrates a comprehensive approach to building an end-to-end machine learning solution for cybersecurity. By combining robust data pipelines, advanced model training techniques, and automated deployment workflows, the system provides reliable phishing detection capabilities that can adapt to evolving threats.
Project Achievements
- Successfully implemented a modular ML pipeline with clear separation of concerns and robust error handling.
- Developed schema-based validation to ensure data quality and consistency throughout the pipeline.
- Integrated experiment tracking with MLflow to maintain reproducibility and facilitate model comparison.
- Created an automated CI/CD pipeline that streamlines the deployment process from code push to production.
- Deployed a scalable solution on AWS with appropriate security controls and monitoring.
Future Improvements
While the current implementation provides robust phishing detection capabilities, several enhancements could further improve the system:
Technical Enhancements
- Implement model monitoring to detect drift in production data
- Add A/B testing framework for model deployment
- Explore deep learning approaches for feature extraction from raw URLs
- Implement online learning capabilities for continuous model updating
User Experience Improvements
- Develop a browser extension for real-time URL scanning
- Create detailed explainability features to highlight phishing indicators
- Add API rate limiting and authentication for production use
- Design an administrative dashboard for monitoring system performance
The ML Phish Detector project stands as a practical demonstration of MLOps principles applied to cybersecurity, showcasing how automated ML pipelines can be leveraged to address real-world security challenges at scale.
Skills Showcased
Machine Learning
- Classification algorithms
- Feature preprocessing
- Hyperparameter tuning
- Model evaluation
- Drift detection
Software Engineering
- Modular code design
- Exception handling
- Logging frameworks
- API development
- Schema validation
MLOps & DevOps
- Docker containerization
- CI/CD automation
- Cloud deployment (AWS)
- Experiment tracking
- Model versioning
Data Engineering
- MongoDB integration
- ETL pipeline design
- Data validation
- Feature store implementation
Pipeline Architecture
- End-to-end ML workflow
- Component modularity
- Pipeline orchestration
- Artifact management
Security Engineering
- Phishing detection
- Feature engineering for security
- URL analysis
- Threat identification
GitHub & Contact Details
Project Repository
github.com/MOHD-AFROZ-ALI/ml-phish-detector
Contact Information
+91 9959786710
linkedin.com/in/mohd-afroz-ali
© 2025 Mohammad Afroz Ali. All rights reserved.
Built with Python, scikit-learn, MLflow, Docker, and AWS