About Me
MOHAMMAD AFROZ ALI
Aspiring SDE, AIML Intern
Education
Final Semester B.Tech (Information Technology)
8.0/10 CGPA
Muffakham Jah College of Engineering & Technology
Focused on
- AI/ML
- Software Engineering
- Cloud Technologies
Interests
Keen on Artificial Intelligence & Machine Learning
Focus on building end-to-end solutions that combine ML with software engineering best practices
Technical Proficiency
Introduction
Text summarization is a crucial natural language processing task that automatically generates concise and coherent summaries from lengthy documents. This project delivers an end-to-end machine learning solution for abstractive text summarization using the powerful T5 (Text-to-Text Transfer Transformer) model.
Project Motivation
With the exponential growth of digital content, there's an increasing need for automated summarization systems that can help users quickly understand the essence of large documents. This project addresses this challenge by implementing a robust, scalable text summarization pipeline.
Dataset Information
The project utilizes the SAMSum dataset, which contains approximately 16,000 messenger-like conversations with their corresponding summaries. This dataset is ideal for training dialogue summarization models as it captures the nuances of conversational text.
Project Overview
Key Features of the Project
Modular Pipeline Architecture
Each component (ingestion, validation, transformation, training, evaluation) is implemented as a separate module with clear interfaces.
T5 Transformer Model
Utilizes Google's T5-small model for high-quality abstractive text summarization with transfer learning capabilities.
Cloud-Native Design
Seamless deployment to AWS infrastructure with containerization via Docker and CI/CD through GitHub Actions.
Automated Workflow
Complete automation from data ingestion to model deployment with robust logging and exception handling.
ROUGE Evaluation
Comprehensive evaluation using ROUGE metrics to assess summary quality and model performance.
FastAPI Integration
RESTful API endpoints for training and prediction with interactive documentation and async support.
Project Workflow Overview
1. Data Ingestion
Download and extract SAMSum dataset from remote source, validate data integrity
2. Data Validation
Verify dataset structure, check for required files (train, test, validation)
3. Data Transformation
Tokenize conversations and summaries using T5 tokenizer, prepare training data
4. Model Training
Fine-tune T5-small model on SAMSum dataset with optimized hyperparameters
5. Model Evaluation
Assess model performance using ROUGE scores and generate evaluation metrics
6. Deployment
Containerize application, deploy to AWS with CI/CD pipeline automation
Data Ingestion
SAMSum Dataset Integration
The data ingestion pipeline automatically downloads the SAMSum dataset from the configured source URL and extracts it to the designated directory. The process ensures data integrity and proper folder structure for subsequent pipeline stages.
Data Source
Dataset: SAMSum Corpus
Size: ~16,000 conversations
Format: JSON with dialogue-summary pairs
Data Structure
- • Train: Training conversations
- • Test: Test conversations
- • Validation: Validation conversations
Configuration Setup
data_ingestion:
root_dir: artifacts/data_ingestion
source_URL: https://github.com/entbappy/Branching-tutorial/raw/master/summarizer-data.zip
local_data_file: artifacts/data_ingestion/data.zip
unzip_dir: artifacts/data_ingestionThe ingestion process creates a structured artifact directory that maintains data versioning and ensures reproducibility across different pipeline runs. The downloaded data is automatically validated for completeness before proceeding to the next stage.
Data Validation
Schema-Based Validation
Data validation ensures the integrity and completeness of the ingested dataset. The process verifies that all required files are present and accessible for the training pipeline.
Validation Checks
- • File existence validation
- • Directory structure verification
- • Data format consistency
- • Schema compliance checking
Required Files
- •
train- Training dataset - •
test- Test dataset - •
validation- Validation dataset
Validation Configuration
data_validation:
root_dir: artifacts/data_validation
STATUS_FILE: artifacts/data_validation/status.txt
ALL_REQUIRED_FILES: ["train", "test", "validation"]Validation Artifacts
- • status.txt: Validation status indicator (True/False)
- • Validation logs: Detailed validation results
- • Error reports: Issues identified during validation
Data Transformation
Tokenization & Preprocessing Pipeline
Data transformation prepares the raw conversation data for training by tokenizing text using the T5 tokenizer. This process converts text into numerical representations that the transformer model can process effectively.
T5 Tokenizer
Model: t5-small
Vocabulary: 32,128 tokens
Special tokens: Text-to-text format
Text Processing
- • Input text tokenization
- • Summary target tokenization
- • Attention mask generation
- • Sequence length management
Transformation Configuration
data_transformation:
root_dir: artifacts/data_transformation
data_path: artifacts/data_ingestion/samsum_dataset
tokenizer_name: t5-smallTokenization Process
1. Text Preprocessing
Clean and normalize conversation text, handle special characters and formatting
2. Input Tokenization
Convert dialogue text to token IDs with appropriate prefixes for T5 text-to-text format
3. Target Tokenization
Tokenize summary text as target sequences for supervised learning
4. Dataset Creation
Create HuggingFace datasets with tokenized inputs and targets for efficient training
Model Training & Fine-tuning
T5-Small Transformer Training
The model training stage fine-tunes the pre-trained T5-small model on the SAMSum dataset using optimized hyperparameters. The training process leverages HuggingFace's Trainer API for efficient distributed training and gradient accumulation.
Model Architecture
Base Model: T5-small
Parameters: 60M
Encoder-Decoder: Transformer
Task: Text-to-text generation
Training Strategy
- • Transfer learning approach
- • Fine-tuning on SAMSum
- • Gradient accumulation
- • Learning rate scheduling
Training Configuration
model_trainer:
root_dir: artifacts/model_trainer
data_path: artifacts/data_transformation/samsum_dataset
model_ckpt: t5-smallTraining Parameters
TrainingArguments:
num_train_epochs: 1
warmup_steps: 500
per_device_train_batch_size: 4
weight_decay: 0.01
logging_steps: 10
evaluation_strategy: steps
eval_steps: 500
save_steps: 1000000
gradient_accumulation_steps: 8Training Highlights
Optimization
- • AdamW optimizer
- • Linear learning rate scheduler
- • Gradient clipping
Memory Efficiency
- • Gradient accumulation
- • Mixed precision training
- • Optimized batch sizes
Model Evaluation
ROUGE Metrics Assessment
Model evaluation employs ROUGE (Recall-Oriented Understudy for Gisting Evaluation) metrics to assess the quality of generated summaries. ROUGE measures the overlap between generated and reference summaries, providing comprehensive evaluation of summarization performance.
ROUGE-1
Measures unigram overlap between generated and reference summaries
ROUGE-2
Evaluates bigram overlap, capturing phrase-level similarity
ROUGE-L
Assesses longest common subsequence, measuring structural similarity
Evaluation Configuration
model_evaluation:
root_dir: artifacts/model_evaluation
data_path: artifacts/data_transformation/samsum_dataset
model_path: artifacts/model_trainer/t5-small-samsum-model
tokenizer_path: artifacts/model_trainer/tokenizer
metric_file_name: artifacts/model_evaluation/metrics.csvEvaluation Process
1. Model Loading
Load fine-tuned T5 model and tokenizer from training artifacts
2. Summary Generation
Generate summaries for test dataset using beam search decoding
3. ROUGE Calculation
Calculate ROUGE-1, ROUGE-2, and ROUGE-L scores against reference summaries
4. Metrics Export
Save evaluation metrics to CSV file for analysis and reporting
Deployment
FastAPI & Docker Containerization
The deployment strategy leverages FastAPI for creating robust REST API endpoints and Docker for containerization. This approach ensures consistent deployment across different environments and provides scalable inference capabilities.
FastAPI Application
- • Async request handling
- • Interactive API documentation
- • Training and prediction endpoints
- • Error handling and logging
Docker Integration
- • Lightweight container image
- • Dependency isolation
- • Cross-platform compatibility
- • Production-ready configuration
FastAPI Implementation
from fastapi import FastAPI
import uvicorn
from textSummarizer.pipeline.prediction import PredictionPipeline
app = FastAPI()
@app.get("/", tags=["authentication"])
async def index():
return RedirectResponse(url="/docs")
@app.get("/train")
async def training():
try:
os.system("python main.py")
return Response("Training successful !!")
except Exception as e:
return Response(f"Error Occurred! {e}")
@app.post("/predict")
async def predict_route(text):
try:
obj = PredictionPipeline()
text = obj.predict(text)
return text
except Exception as e:
raise e
if __name__=="__main__":
uvicorn.run(app, host="0.0.0.0", port=8080)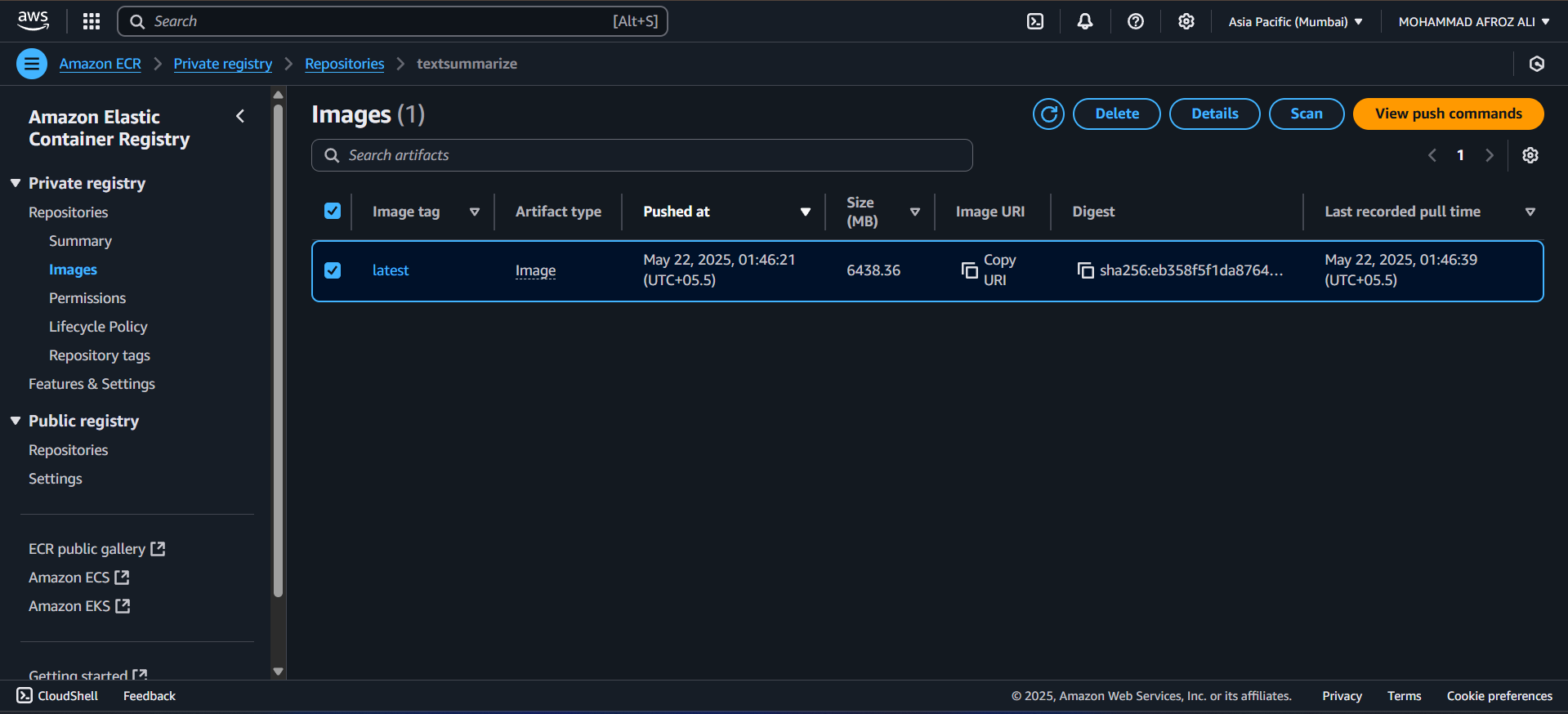
Docker Configuration
FROM python:3.8-slim-buster
RUN apt update -y && apt install awscli -y
WORKDIR /app
COPY . /app
RUN apt-get update && apt-get install -y build-essential python3-dev
RUN pip install -r requirements.txt
RUN pip install --upgrade accelerate
RUN pip uninstall -y transformers accelerate
RUN pip install transformers accelerate
CMD ["python3", "app.py"]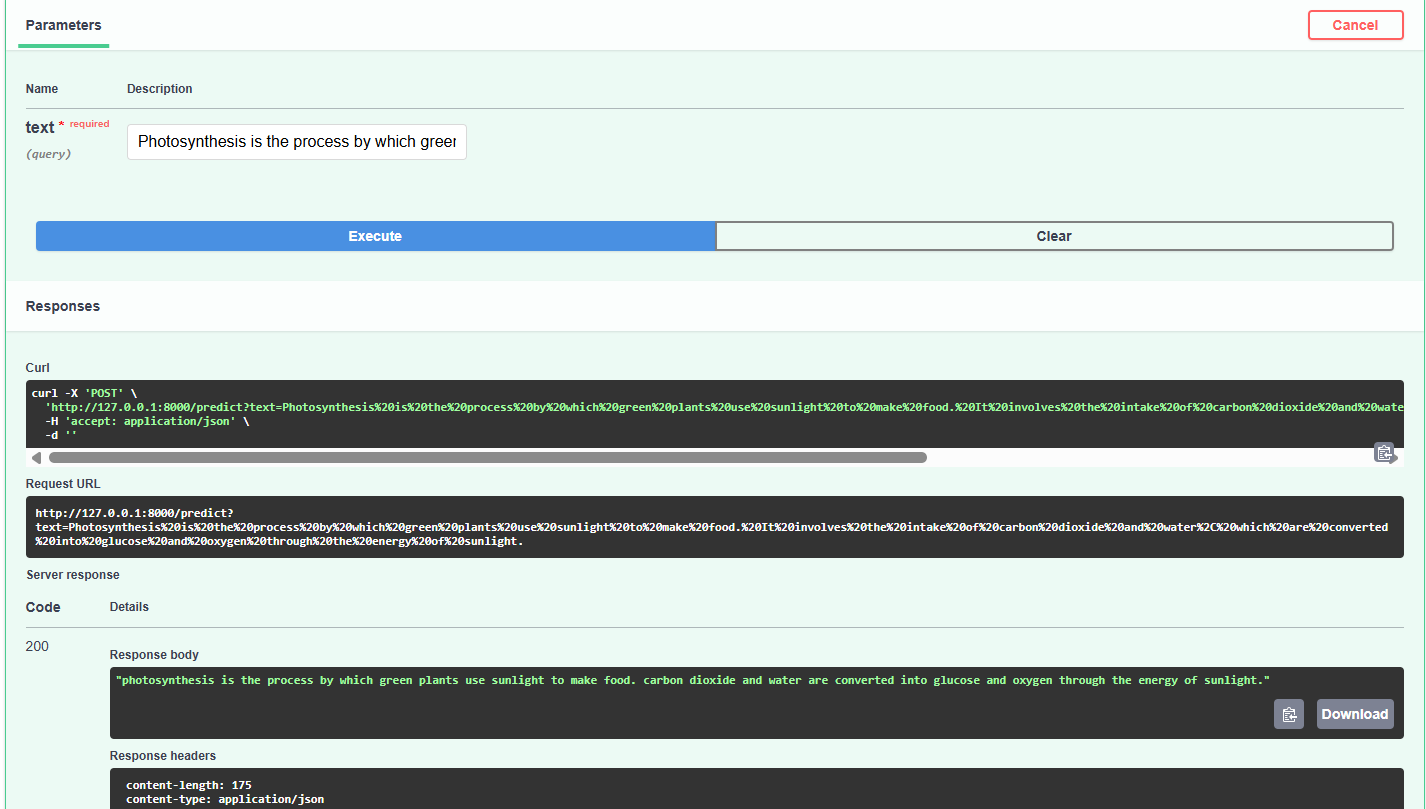
API Endpoints
GET /
Redirects to interactive API documentation
GET /train
Triggers complete training pipeline execution
POST /predict
Accepts text input and returns generated summary
GET /docs
Automatic OpenAPI documentation interface
CI/CD Pipeline & AWS Deployment
GitHub Actions Workflow
The CI/CD pipeline automates the entire deployment process from code push to production deployment on AWS. The workflow includes testing, building Docker images, pushing to AWS ECR, and deploying to EC2 instances.
GitHub Actions
- • Automated testing
- • Docker image building
- • AWS integration
- • Deployment automation
AWS Services
- • ECR (Container Registry)
- • EC2 (Compute)
- • IAM (Access Management)
- • S3 (Storage)
AWS Deployment Architecture
1. IAM User Creation
Create IAM user with specific permissions for EC2 and ECR access
2. ECR Repository Setup
Create Elastic Container Registry to store Docker images
3. EC2 Instance Configuration
Launch Ubuntu EC2 instance and install Docker
4. Self-Hosted Runner Setup
Configure EC2 as GitHub Actions self-hosted runner
Required AWS Policies
# IAM Policies Required:
1. AmazonEC2ContainerRegistryFullAccess
2. AmazonEC2FullAccess
# Description: About the deployment
1. Build docker image of the source code
2. Push your docker image to ECR
3. Launch Your EC2
4. Pull Your image from ECR in EC2
5. Launch your docker image in EC2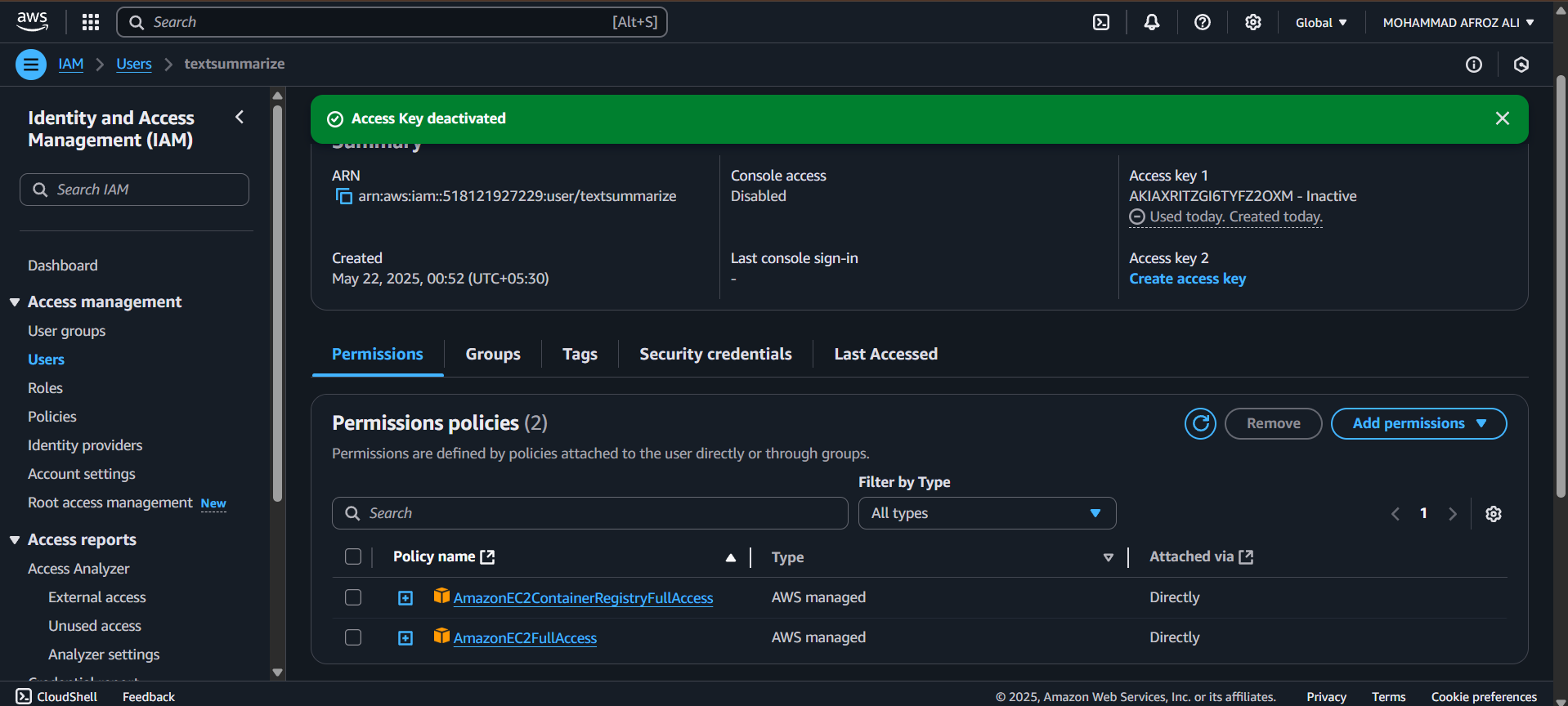
GitHub Secrets Configuration
AWS_ACCESS_KEY_ID=your_access_key
AWS_SECRET_ACCESS_KEY=your_secret_key
AWS_REGION=us-east-1
AWS_ECR_LOGIN_URI=12345678.dkr.ecr.us-east-1.amazonaws.com
ECR_REPOSITORY_NAME=textsummarize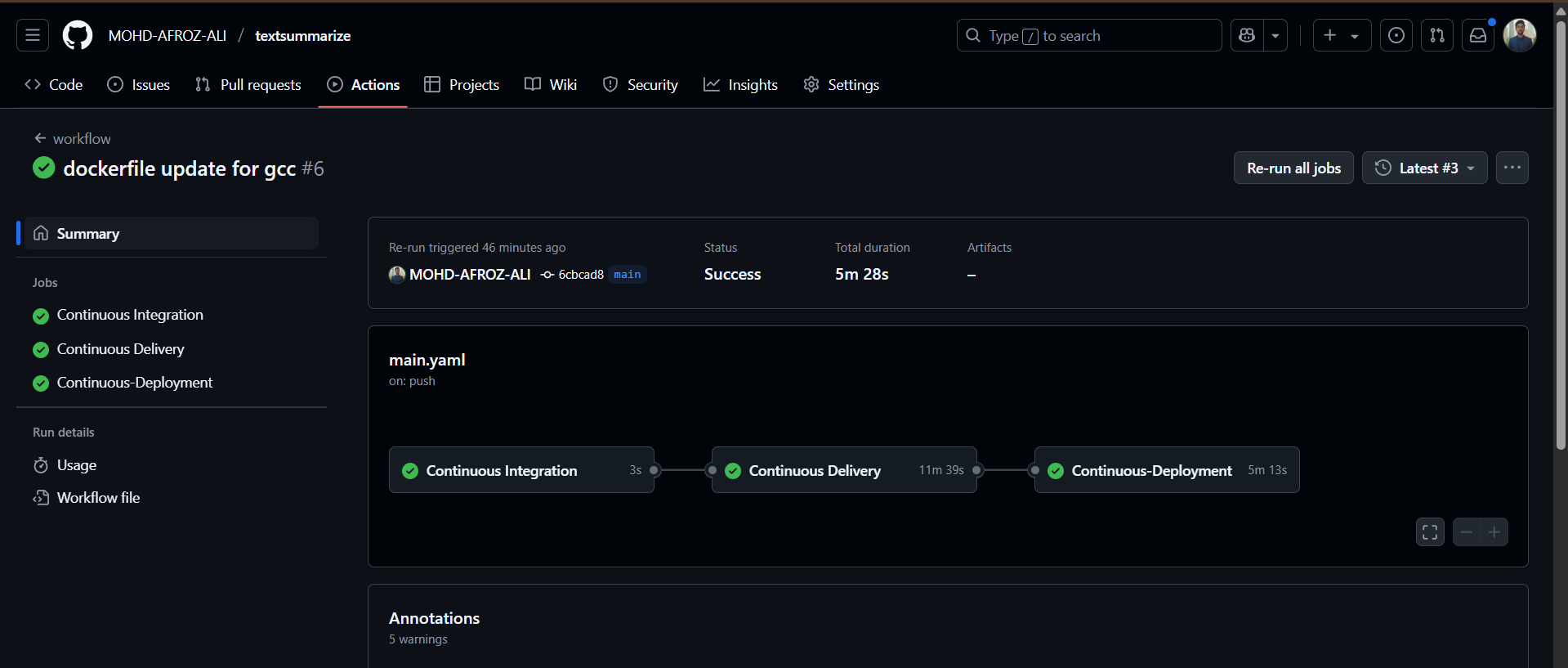
Docker Installation on EC2
# Optional
sudo apt-get update -y
sudo apt-get upgrade
# Required
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
sudo usermod -aG docker ubuntu
newgrp docker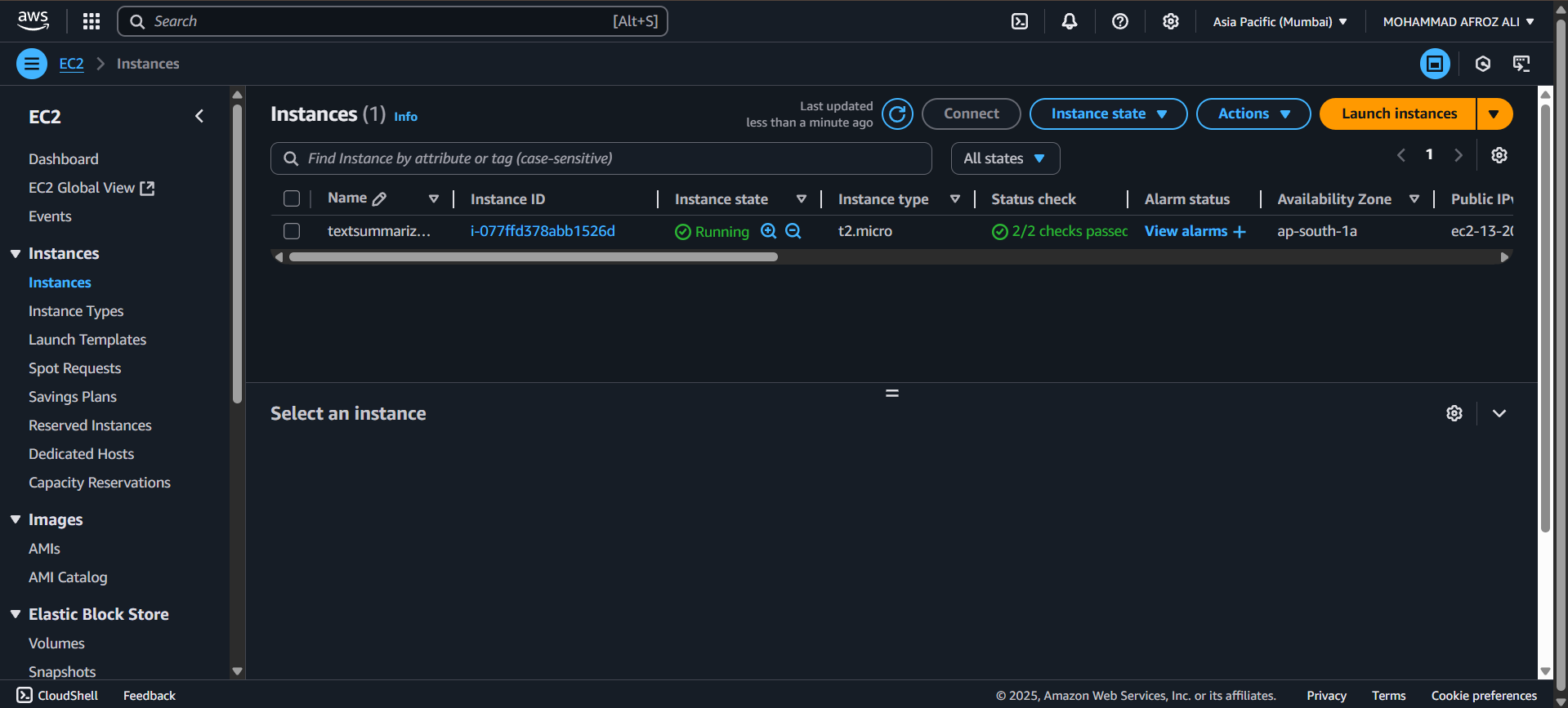
Skills Showcased
Natural Language Processing
- • Transformer models (T5)
- • Text summarization
- • Tokenization & preprocessing
- • ROUGE evaluation metrics
- • HuggingFace ecosystem
Software Engineering
- • Modular code architecture
- • Object-oriented programming
- • Exception handling
- • Configuration management
- • API development (FastAPI)
MLOps & DevOps
- • Docker containerization
- • CI/CD pipelines
- • GitHub Actions
- • Model versioning
- • Pipeline orchestration
Cloud Computing
- • AWS EC2 deployment
- • AWS ECR container registry
- • IAM security management
- • Cloud infrastructure
- • Scalable deployments
Data Engineering
- • Data pipeline design
- • ETL processes
- • Data validation
- • Schema management
- • Artifact management
Technical Tools
- • Python ecosystem
- • PyTorch framework
- • Transformers library
- • YAML configuration
- • REST API design
GitHub & Contact Details
Project Repository
Access the complete source code, documentation, and implementation details:
View RepositoryContact Information
© 2025 Mohammad Afroz Ali. All rights reserved.
Built with Python, Transformers, FastAPI, Docker, and AWS